

What is a data operations center?
Learn MoreWhat is a data operations center?
Learn More

.png)
Pantomath rebuilt incident resolution around purpose-built AI agents: a fast triage step routes each data incident to a specialist grounded in your lineage.
Pantomath's Purpose-Built AI Agents: Why We Replaced One Agent with a Team of Specialists

How we rebuilt Pantomath’s incident resolution from a single generalist into a roster of purpose-built experts — and why your recommendations got sharper because of it.
SIgn up for our July 9th AI Agent Demo with Jeremy HERE
One AI, every kind of failure
When we set out to have Pantomath not just detect data incidents but resolve them, we did the obvious thing: we built one smart AI agent and asked it to handle everything. A pipeline breaks at 2 a.m. — a credential expires, a SQL model won’t compile, a schema drifts, a warehouse runs out of memory — and the same agent would read the error, study your environment using the wide range of context Pantomath is able to pull, assess impact, generate an RCA, and a prepare recommended resolution plan.
It was a clean idea. It was also the same mistake a growing operations team eventually learns to stop making: you don’t send one generalist to every incident. The engineer who lives and breathes credential rotation is not the one you want untangling a subtle change-data-capture fault, and vice versa. The work is too varied, and the cost of a confidently wrong answer at 2 a.m. is too high.
Why the generalist hit a ceiling
Here’s what we ran into. To make one agent competent at everything, we had to cram everything into one set of instructions: how to reason about access errors and SQL compilation and schema conflicts and capacity limits and network timeouts and ingestion failures and replication faults. Each of those domains has its own vocabulary, its own diagnostic order, and its own idea of what a good fix looks like.
A single set of instructions carrying all of that is a little distracting in every individual case. The agent knew a little about a lot — exactly the wrong shape for incident response, where the gap between a useful recommendation and a dangerous one is often a domain-specific detail: the right place to rotate a key, the right way to widen a column without breaking everything reading from it downstream, not to mention, the right way to do apply these actions in numerous enterprise data platforms.
It was also nearly impossible to improve with confidence. When everything lives in one agent, tightening its handling of, say, schema conflicts risks quietly degrading how it handles access errors. We couldn’t measure one skill in isolation, and we couldn’t change one skill without holding our breath about the others. For a system whose entire job is to be trustworthy under pressure, that ceiling was unacceptable.
The reframe: a team of specialists
So we did what a maturing response team does. We hired specialists.
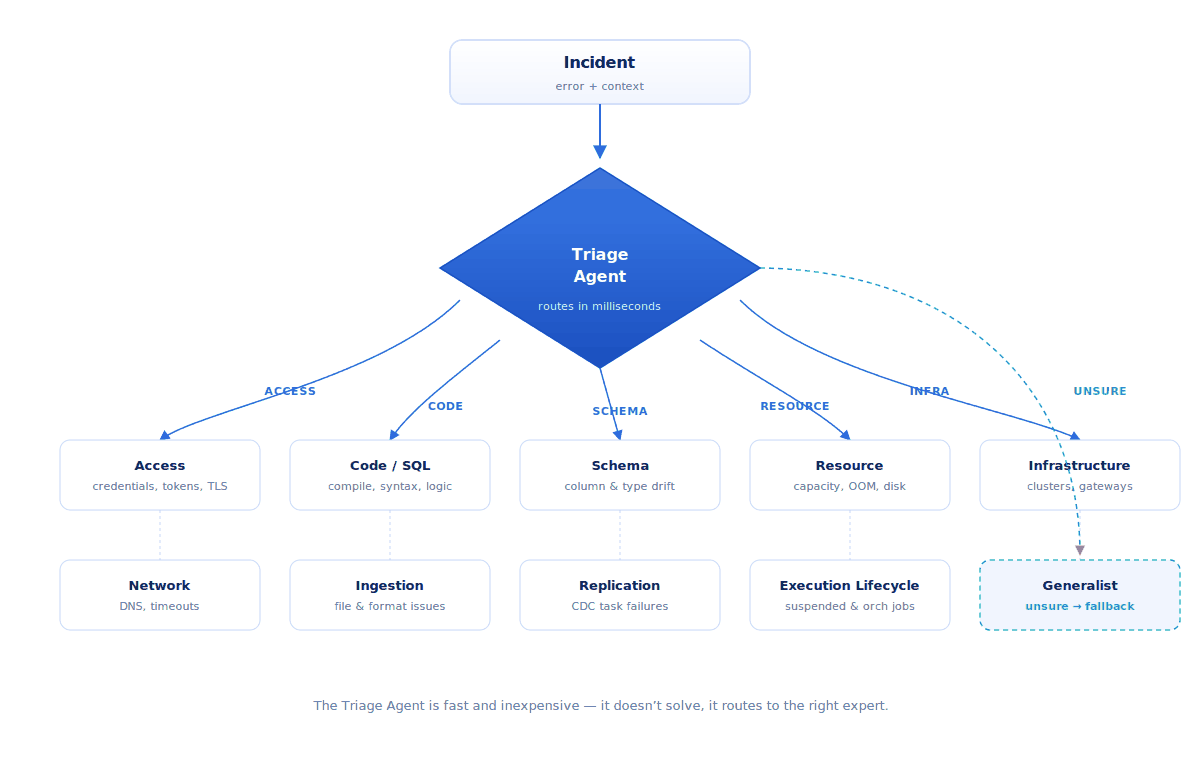
Instead of one agent that knows a little about every failure, Pantomath now runs a roster of purpose-built agents, each an expert in a single family of incidents:
- Access — credentials, permissions, tokens, TLS and certificates
- Code / SQL — compilation errors, syntax, runtime and logic failures
- Schema conflicts — column and type drift between systems
- Resource exhaustion — capacity limits, out-of-memory, disk pressure
- Infrastructure — clusters, warehouses, gateways, bridges
- Network / connectivity — timeouts, DNS, remote-service errors
- Ingestion — file and format problems, source-data availability
- Replication — change-data-capture task failures
- Execution lifecycle — suspended tasks and job-orchestration failures
…plus a careful generalist that catches anything the specialists shouldn’t claim.
The important design choice: these specialists are not separate products bolted together. They share one rigorous engine — the same reasoning loop, the same safety checks, the same way of validating a plan before it ever reaches you. What differs is expertise. Each specialist carries only the knowledge, examples, and judgment relevant to its domain. We think of it as a shared chassis with specialized expertise: the shared chassis is why adding or sharpening a specialist is fast; the specialization is why each one is good.
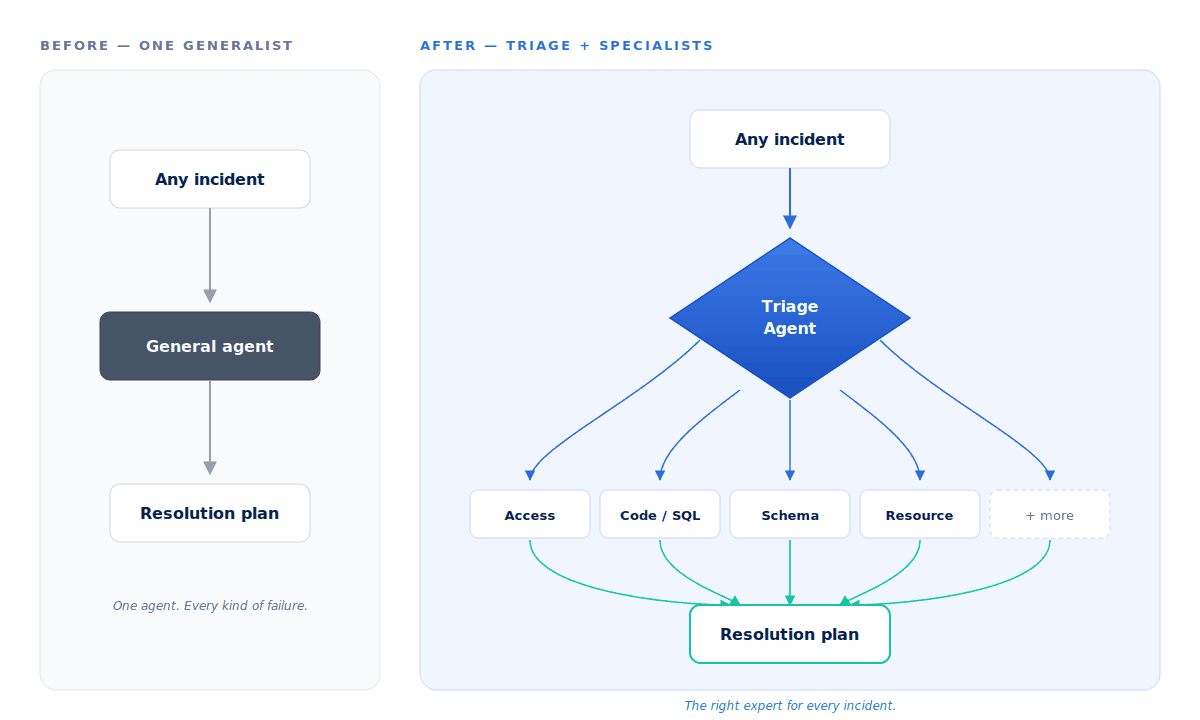
How triage routes each incident
If you have specialists, you need a good triage desk. So the first thing that happens to any incident is the Triage Agent — a fast, lightweight agent whose only job is to triage and route. It reads the error and the context and decides what kind of problem this is — access, code, schema, and so on. It’s deliberately quick and inexpensive; it doesn’t try to solve anything, it just gets the incident to the right expert.
Once the incident is categorized, it’s handed to the matching specialist. If the Triage Agent isn’t confident — the error is genuinely ambiguous, or it’s something we don’t yet have a dedicated expert for — the incident goes to the generalist instead of being forced into a bad fit. Routing to the wrong specialist is worse than routing to a capable generalist, and the system is built to know the difference.
There’s a quieter benefit to triaging first: we can run the right model for each job. A specialist resolving a tricky schema conflict can lean on a more powerful model, while the Triage Agent itself uses a lean, quick one. Matching the model to the difficulty of the task keeps responses both sharp and fast — you’re never waiting on an oversized model to answer a simple routing question.
Three incidents, three specialists
Here’s how it plays out across three different failures. (The details are composited; the shape is real.)
An access failure, 2:14 a.m. An overnight load that feeds your finance dashboards fails with a permission denial from the warehouse — a rotated service-account password that was never updated in the connector. The Triage Agent reads the failure and routes it to the Access specialist, which doesn’t start guessing. It pulls the incident’s real lineage — the broken connection, the load job that depends on it, the tables that job writes, and the dashboards downstream of those tables — and runs an impact analysis to see what’s at risk and when each downstream job next runs. Then it writes a plan grounded in your environment: update the stored credential in the connector that failed, re-grant the privileges the service account lost, validate with a quick test query, and re-run that specific load job — before the 6 a.m. dashboard refresh the impact analysis flagged as the first thing your finance team would notice. No “check your credentials” boilerplate; a concrete sequence, naming your objects, ordered by real downstream urgency.
A code failure, mid-pipeline. A transformation model won’t compile: a column an upstream team renamed yesterday is still referenced by its old name in a downstream model’s SQL. The Triage Agent routes it to the Code / SQL specialist, which reads the compilation error, follows the lineage back to the model where the column was renamed and forward to every model and dashboard that depends on the one that’s failing. It returns an actual code-level fix — the corrected SQL with the right column reference, not a vague “check your query” — and flags the specific downstream models that will need a rebuild once the fix lands. The hard part of a code incident isn’t noticing that it broke; it’s knowing precisely what to change and what else moves when you do. That’s the part a specialist gets right.
A schema conflict, on load. A source system starts sending a field that used to be a short string as a much longer one, and rows begin getting rejected for exceeding the target column’s length. The Triage Agent routes it to the Schema specialist, which works from the column-level diff between what’s arriving and what the target expects. It pinpoints the exact column, enumerates the views and tables reading from it, and recommends a safe resolution path — widen the target column to fit the new data in a way that won’t break the downstream consumers it just listed. A schema change is only safe if you can see everything that depends on the column you’re about to touch; the specialist reasons over that graph before it recommends the change.
Grounded in your lineage, not templates
That grounding is the part we care about most, because it’s the part that earns trust at 2 a.m.
Every specialist works from your actual data lineage. When it names a table, a job, or a column in a recommendation, that name comes from your environment — not from a template, and not invented to sound plausible. And because each specialist runs an impact analysis across the downstream graph, it can tell you not just what to fix but what’s riding on it: which jobs and datasets are affected, and which ones are about to run.
This matters because the failure mode of generic AI advice isn’t being unhelpful — it’s being confidently generic. A recommendation that references the wrong object, or a fix that quietly breaks three downstream consumers, costs more than no recommendation at all. Anchoring every plan to your real lineage and downstream impact is how we keep the advice specific enough to act on without launching a second investigation just to verify it.
How we proved it’s better
We didn’t take the improvement on faith. Every specialist is evaluated independently against a library of held-out, real-world incident scenarios, scored across many dimensions of quality: is the plan grounded, is it concrete, does it cite real objects, does it break the investigation into the right steps, is the suggested code sound.
Two things showed up clearly. First, the specialists clear a high quality bar across the board. Second — and more tellingly — they beat the old generalist most on the hardest parts of the job: breaking a messy incident into the right sequence of investigation steps, and the quality of code-level fixes. Those are double-digit improvements on exactly the dimensions that separate a plan you can run from a plan you have to re-investigate.
Because each specialist has its own independent evaluation, we can now sharpen one without risking the others. Improving how we handle schema conflicts no longer means holding our breath about access errors. Every specialist gets better on its own track — which means the system as a whole keeps improving, steadily and safely.
What this means for your on-call
For your team, none of this architecture is visible — and that’s the point. What you see is a recommendation that reads like it came from someone who actually knows your environment: specific, grounded in your lineage, aware of what’s downstream, and right about the part that matters.
We rebuilt incident resolution as a team of specialists because that’s what it takes to be trustworthy across the full, messy range of things that break in a modern data stack. The next time Pantomath hands your on-call engineer a plan at 2 a.m., it’s because the right expert took the case.
See the agents in action during Jeremy's Demo on July 9th - SIGN UP HERE
Keep Reading
.png)
May 14, 2026
Rebuilding Lineage for Enterprise ScaleAt enterprise scale, data lineage stops being a UI feature and becomes a systems problem. We rebuilt Pantomath's Lineage Explorer from the ground up, new renderer, new data layer, new layout engine, to handle thousands of nodes without breaking a sweat.
Read More.png)
May 8, 2026
The Silent Killer of Enterprise AI: Why Your Agents Need a "Data Pulse"AI agents trust whatever data they're handed and fail confidently when it's wrong. Pantomath gives them an upstream data health check before they act.
Read More.png)
April 2, 2026
The Rise of the Data Reliability Engineer (DRE) and the Future of Data OperationsThe DRE is becoming essential as data systems grow more complex. Learn how this role helps teams reduce incidents, speed up root cause analysis, and keep data on time and accurate.
Read More

