

What is a data operations center?
Learn MoreWhat is a data operations center?
Learn More


CIOs and CDOs are blindsided by massive hidden costs in their data investments — and they’re not what you'd expect.
Your Data Platform TCO is 3x Higher Than You Think

You've made big investments: Snowflake, Databricks, several other components of the modern data stack. Your board sees the seven-figure software spend and asks the inevitable question: "What's the ROI on data platforms?"
Many data leaders are just beginning to realize that for every dollar they spend on data platform licenses, they may be spending way more on related services, optimization, and support. The real cost isn't the Snowflake bill. It's the army of other resources who manually keep the data pipelines up and running. ETL workloads, for example, can account for 50% or more of an organization’s overall data costs.
According to one Reddit user weighing Snowflake versus Databricks, “Databricks is usually cheaper because it gives you many knobs, bells and whistles to fine tune your workloads. The downside is that you have many more knobs, bells and whistles to fine tune your workloads.” Who is doing the fine-tuning, and how much does that cost?
Let’s take a deeper look into why your data platform total cost of ownership (“TCO”) is higher than it may appear at first glance.
The Invisible Army Managing Your Data
Much of the manual support work required by data platforms is managed by off-shore support resources. Fortune 500 companies rely on hundreds of support engineers from TCS, Wipro, Infosys, Cognizant, and other BPO providers, manually babysitting what should be automated systems.
Recent research shows that 90% of organizations take hours to weeks to resolve pipeline issues, with 74% relying on downstream teams to detect problems in the first place. This isn't just inefficiency. It’s systematic dysfunction masquerading as "standard practice."
The three-tier support model that most enterprises use for data operations is a relic from the mainframe era, retrofitted for modern data complexity.
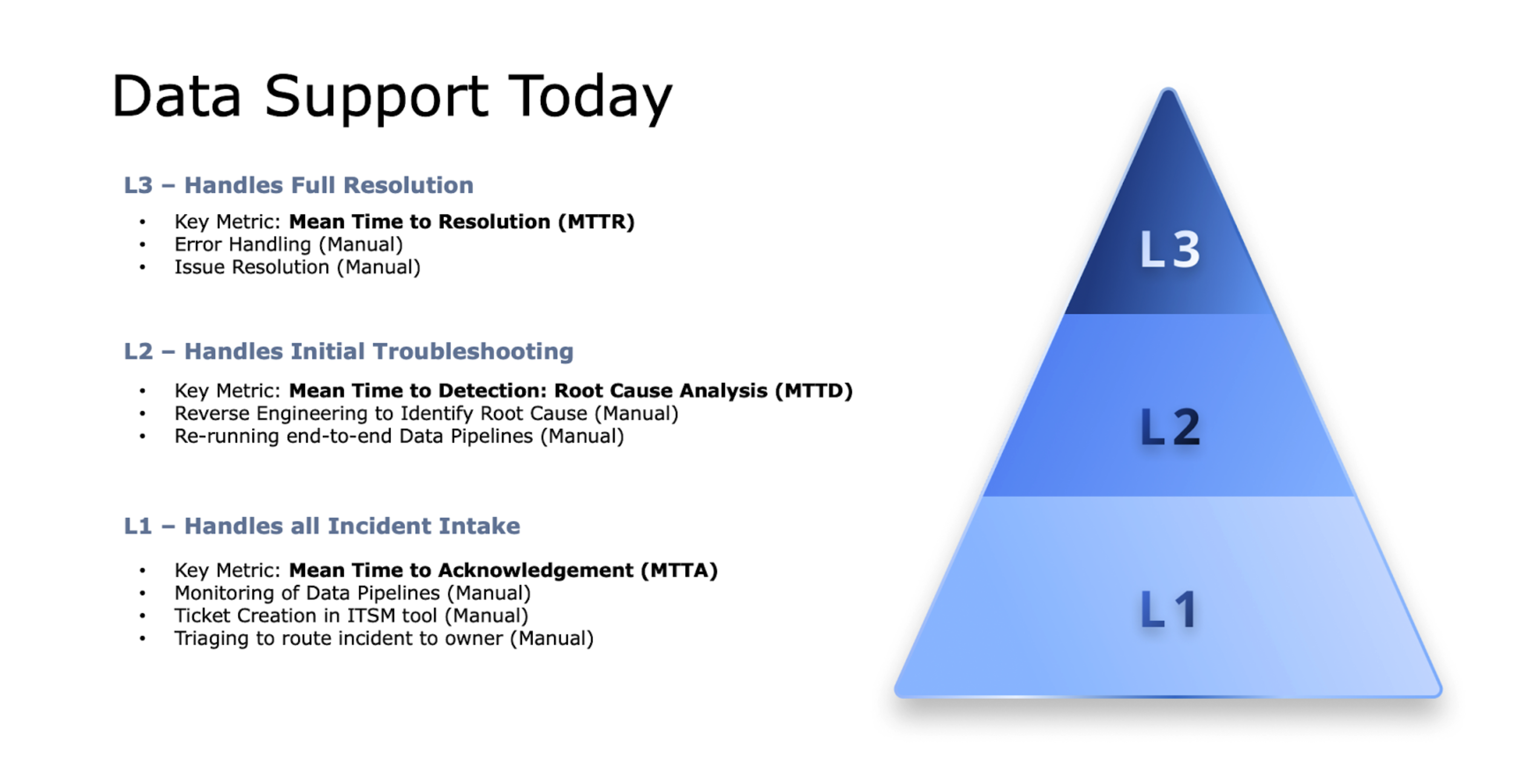
L1 teams (the first responders)
Your L1 support team is the first line of defense for issues reported by end users. They often work with little context, troubleshooting in isolation without visibility into the jobs that feed the warehouse powering those reports. By the time they spot a problem, it’s already impacting end users. Their main strength is escalating complex issues and hitting Mean Time to Acknowledgement (MTTA) SLAs. But their work is inherently reactive, built around box-checking and scripted triage rather than preventing issues or resolving them quickly.
L2 teams (the support engineers)
All incidents that can’t be resolved through basic standard operating procedures (“SOPs”) escalate to the L2 team. These engineers spend their days reverse-engineering data pipelines that were built by teams who've long since moved on. They're essentially digital archaeologists, piecing together fragments of tribal knowledge and outdated documentation to find root causes through manual troubleshooting.
If the root cause is identified, they resolve the issue in some cases. In other cases, they may not have the right access or permission to make the requisite changes. In those cases, they’ll route the incident up to the L3 support team, after meeting their SLA for Mean Time to Detection (“MTTD”).
L3 teams (senior technical resources)
Your most expensive resources are often your senior data engineers and experienced admins. These experts rely heavily on their experience and tribal knowledge to manually resolve issues. Frequently, they must reverse-engineer entire data pipelines just to restore operations, even when the root cause is a single data integration job failure in a tool like Informatica. The manual recovery process is extremely time-consuming. This team is measured by the Mean Time to Resolution (“MTTR”) SLA, as they ultimately own the outcome.
What compounds inefficiency at this stage is how incidents are tracked in ITSM tools like ServiceNow. When a single upstream failure disrupts 15 Tableau reports, 15 separate tickets are created, each timestamped when a user discovers the issue, not when the failure actually occurred.
This leads to two major problems: first, SLA and SLI metrics in ServiceNow reflect user discovery, not the true incident window, masking the real impact of data downtime. Second, L3 engineers waste their time resolving what appear to be separate incidents but are actually all symptoms of the same root cause.
The Case for Automation: Flipping the Model
The current state of data operations is ripe for transformation. An automation-first approach can help organizations detect issues in real time, and flip the current model on its head. Often, this automated approach can autocreate tickets in ITSM tools, or even resolve incidents without any human intervention at all. AI-driven solutions like Pantomath’s AI DRE Agents can help bridge the gap. Here’s what they deliver.
What automated AI DRE agents deliver
Automated monitoring – Machine learning-based monitors for datasets and jobs across platforms like Snowflake, covering data volume, freshness, failures, and latency.
Seamless ITSM integration – Automatic ticket creation and population in ServiceNow and Jira, reducing manual overhead and duplication.
Smart incident management – Bi-directional integrations that auto-triage incidents to the right teams and manage the incident lifecycle.
Root cause analysis and resolution – Streamlined RCA today, with future capabilities for fully automated, AI-driven diagnosis and remediation—moving from recommendations to autonomous action.
End-to-end issue resolution – Cross-platform impact analysis and guided resolution, with a roadmap toward self-healing pipelines that leverage a data health graph to orchestrate recovery across systems.
Proactive alerting - Persona-based notifications to support and consumer teams via MS Teams, Slack, PagerDuty, and more, with future integration into Snowflake Intelligence.
Fixing the TCO problem with automated data operations
The three-tier support model that seemed logical in the mainframe era has become a productivity drain in the age of interconnected data ecosystems.
The choice facing data leaders today isn't whether to automate. It's how quickly they can transform their operations before competitors do. Organizations that stay stubbornly manual will find themselves increasingly disadvantaged, spending exponentially more to achieve the same outcomes as their automated counterparts.
The TCO problem extends far beyond software licensing costs. It's fundamentally about how organizations allocate their most valuable resource: human expertise. With automation and integrated observability now readily available, transforming data operations isn’t a future goal. It’s an immediate opportunity to reduce costs and let your experts focus on what matters most.
If you’re ready to save on the TCO of your data platforms, learn how Pantomath's automated data operations platform can help you accelerate the journey.
Keep Reading
.png)
June 5, 2026
Snowflake Summit 26 Recap: The Agentic Enterprise and the Cross-Platform Gap It Leaves OpenOur team was onsite at Snowflake Summit 2026 and here's what stuck and where we think the story isn't finished yet.
Read More.png)
May 14, 2026
Rebuilding Lineage for Enterprise ScaleAt enterprise scale, data lineage stops being a UI feature and becomes a systems problem. We rebuilt Pantomath's Lineage Explorer from the ground up, new renderer, new data layer, new layout engine, to handle thousands of nodes without breaking a sweat.
Read More.png)
May 8, 2026
The Silent Killer of Enterprise AI: Why Your Agents Need a "Data Pulse"AI agents trust whatever data they're handed and fail confidently when it's wrong. Pantomath gives them an upstream data health check before they act.
Read More

